
Supercomputers
by Chris Woodford. Last updated: March 28, 2023.
Roll back time a half-century or so and the smallest computer in the world was a gargantuan machine that filled a room. When transistors and integrated circuits were developed, computers could pack the same power into microchips as big as your fingernail. So what if you build a room-sized computer today and fill it full of those same chips? What you get is a supercomputer—a computer that's millions of times faster than a desktop PC and capable of crunching the world's most complex scientific problems. What makes supercomputers different from the machine you're using right now? Let's take a closer look!
Photo: This is Frontier, a scientific supercomputer based at Oak Ridge National Laboratory. It's currently the world's most powerful machine, with some 8,730,112 processor cores, and it set a new performance record of 1.1 exaflops (1.1 million million million flops) in 2022. Picture courtesy of Oak Ridge National Laboratory, US Department of Energy, published on Flickr in 2022 under a Creative Commons (CC BY 2.0) Licence.
Sponsored links

Listen instead... or scroll to keep reading
Contents
What is a supercomputer?
Before we make a start on that question, it helps if we understand what a computer is: it's a general-purpose machine that takes in information (data) by a process called input, stores and processes it, and then generates some kind of output (result). A supercomputer is not simply a fast or very large computer: it works in an entirely different way, typically using parallel processing instead of the serial processing that an ordinary computer uses. Instead of doing one thing at a time, it does many things at once.
Serial and parallel processing
What's the difference between serial and parallel? An ordinary computer does one thing at a time, so it does things in a distinct series of operations; that's called serial processing. It's a bit like a person sitting at a grocery store checkout, picking up items from the conveyor belt, running them through the scanner, and then passing them on for you to pack in your bags. It doesn't matter how fast you load things onto the belt or how fast you pack them: the speed at which you check out your shopping is entirely determined by how fast the operator can scan and process the items, which is always one at a time. (Since computers first appeared, most have worked by simple, serial processing, inspired by a basic theoretical design called a Turing machine, originally conceived by Alan Turing.)
A typical modern supercomputer works much more quickly by splitting problems into pieces and working on many pieces at once, which is called parallel processing. It's like arriving at the checkout with a giant cart full of items, but then splitting your items up between several different friends. Each friend can go through a separate checkout with a few of the items and pay separately. Once you've all paid, you can get together again, load up the cart, and leave. The more items there are and the more friends you have, the faster it gets to do things by parallel processing—at least, in theory. Parallel processing is more like what happens in our brains.
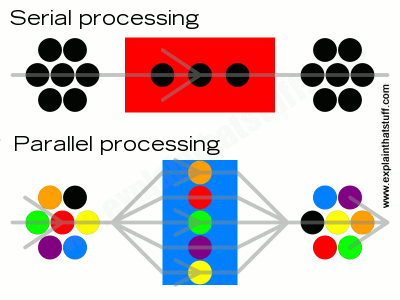
Artwork: Serial and parallel processing: Top: In serial processing, a problem is tackled one step at a time by a single processor. It doesn't matter how fast different parts of the computer are (such as the input/output or memory), the job still gets done at the speed of the central processor in the middle. Bottom: In parallel processing, problems are broken up into components, each of which is handled by a separate processor. Since the processors are working in parallel, the problem is usually tackled more quickly even if the processors work at the same speed as the one in a serial system.
Why do supercomputers use parallel processing?
Most of us do quite trivial, everyday things with our computers that don't tax them in any way: looking at web pages, sending emails, and writing documents use very little of the processing power in a typical PC. But if you try to do something more complex, like changing the colors on a very large digital photograph, you'll know that your computer does, occasionally, have to work hard to do things: it can take a minute or so to do really complex operations on very large digital photos. If you play computer games, you'll be aware that you need a computer with a fast processor chip and quite a lot of "working memory" (RAM), or things really slow down. Add a faster processor or double the memory and your computer will speed up dramatically—but there's still a limit to how fast it will go: one processor can generally only do one thing at a time.
Now suppose you're a scientist charged with forecasting the weather, testing a new cancer drug, or modeling how the climate might be in 2050. Problems like that push even the world's best computers to the limit. Just like you can upgrade a desktop PC with a better processor and more memory, so you can do the same with a world-class computer. But there's still a limit to how fast a processor will work and there's only so much difference more memory will make. The best way to make a difference is to use parallel processing: add more processors, split your problem into chunks, and get each processor working on a separate chunk of your problem in parallel.

Chart: Who has the most supercomputers? About three quarters of the world's 500 most powerful machines can be found in just five countries: China (32.4%), the USA (25.4%), Germany (6.8%), Japan (6.2%), and France (4.8%). For each country, the series of bars show its total number of supercomputers in 2017, 2018, 2020, 2021, and 2023. The block on the right of each series, with a bold number in red above, shows the current figure for November 2022. Although China has the most machines by far, the aggregate performance of the US machines is significantly higher (representing almost half the world's supercomputer total performance, according to TOP500's analysis). Drawn in March 2023 using the latest data from TOP500, November 2022.
Massively parallel computers
Once computer scientists had figured out the basic idea of parallel processing, it made sense to add more and more processors: why have a computer with two or three processors when you can have one with hundreds or even thousands? Since the 1990s, supercomputers have routinely used many thousands of processors in what's known as massively parallel processing; at the time I'm updating this, in March 2023, the supercomputer with more processors than any other in the world, the Sunway TaihuLight, has around 40,960 processing modules, each with 260 processor cores, which means 10,649,600 processor cores in total! (It's currently the world's seventh most powerful machine.)
Unfortunately, parallel processing comes with a built-in drawback. Let's go back to the supermarket analogy. If you and your friends decide to split up your shopping to go through multiple checkouts at once, the time you save by doing this is obviously reduced by the time it takes you to go your separate ways, figure out who's going to buy what, and come together again at the end. We can guess, intuitively, that the more processors there are in a supercomputer, the harder it will probably be to break up problems and reassemble them to make maximum efficient use of parallel processing. Moreover, there will need to be some sort of centralized management system or coordinator to split the problems, allocate and control the workload between all the different processors, and reassemble the results, which will also carry an overhead.
With a simple problem like paying for a cart of shopping, that's not really an issue. But imagine if your cart contains a billion items and you have 65,000 friends helping you with the checkout. If you have a problem (like forecasting the world's weather for next week) that seems to split neatly into separate sub-problems (making forecasts for each separate country), that's one thing. Computer scientists refer to complex problems like this, which can be split up easily into independent pieces, as embarrassingly parallel computations (EPC)—because they are trivially easy to divide.
But most problems don't cleave neatly that way. The weather in one country depends to a great extent on the weather in other places, so making a forecast for one country will need to take account of forecasts elsewhere. Often, the parallel processors in a supercomputer will need to communicate with one another as they solve their own bits of the problems. Or one processor might have to wait for results from another before it can do a particular job. A typical problem worked on by a massively parallel computer will thus fall somewhere between the two extremes of a completely serial problem (where every single step has to be done in an exact sequence) and an embarrassingly parallel one; while some parts can be solved in parallel, other parts will need to be solved in a serial way. A law of computing (known as Amdahl's law, for computer pioneer Gene Amdahl), explains how the part of the problem that remains serial effectively determines the maximum improvement in speed you can get from using a parallel system.
Clusters
You can make a supercomputer by filling a giant box with processors and getting them to cooperate on tackling a complex problem through massively parallel processing. Alternatively, you could just buy a load of off-the-shelf PCs, put them in the same room, and interconnect them using a very fast local area network (LAN) so they work in a broadly similar way. That kind of supercomputer is called a cluster. Google does its web searches for users with clusters of off-the-shelf computers dotted in data centers around the world.

Photo: Supercomputer cluster: NASA's Pleiades ICE Supercomputer is a cluster of 241,108 cores made from 158 racks of Silicon Graphics (SGI) workstations. That means it can easily be extendedto make a more powerful machine: it's now about 15 times more powerful than when it was first built over a decade ago. As of March 2023, it's the world's 97th most powerful machine (compared to 2021, when it was 70th, and 2020, when it stood at number 40). Picture by Dominic Hart courtesy of NASA Ames Research Center.
Grids
A grid is a supercomputer similar to a cluster (in that it's made up of separate computers), but the computers are in different places and connected through the Internet (or other computer networks). This is an example of distributed computing, which means that the power of a computer is spread across multiple locations instead of being located in one, single place (that's sometimes called centralized computing).
Grid super computing comes in two main flavors. In one kind, we might have, say, a dozen powerful mainframe computers in universities linked together by a network to form a supercomputer grid. Not all the computers will be actively working in the grid all the time, but generally we know which computers make up the network. The CERN Worldwide LHC Computing Grid, assembled to process data from the LHC (Large Hadron Collider) particle accelerator, is an example of this kind of system. It consists of two tiers of computer systems, with 11 major (tier-1) computer centers linked directly to the CERN laboratory by private networks, which are themselves linked to 160 smaller (tier-2) computer centers around the world (mostly in universities and other research centers), using a combination of the Internet and private networks.
The other kind of grid is much more ad-hoc and informal and involves far more individual computers—typically ordinary home computers. Have you ever taken part in an online computing project such as SETI@home, GIMPS, FightAIDS@home, Folding@home, MilkyWay@home, or ClimatePrediction.net? If so, you've allowed your computer to be used as part of an informal, ad-hoc supercomputer grid. This kind of approach is called opportunistic supercomputing, because it takes advantage of whatever computers just happen to be available at the time. Grids like this, which are linked using the Internet, are best for solving embarrassingly parallel problems that easily break up into completely independent chunks.




